Balance means letting AI do the fast, repetitive, low-risk work while people own scoping, edge cases, and final decisions. It’s a centaur stance of assistive and not substitutive. But when is it the right time to automate vs. review vs. decide? Automate when tasks are reversible and well-scoped. Review when impact or ambiguity rises. Decide when the outcome affects people, money, or reputation.
“It is important to see AI as a tool that helps humans, not one that takes their place.” (Public Sector Network, 2024)
Why balance matters now
AI is already threaded through daily life. That ubiquity arrives with an oversight gap: “AI does in fact affect every part of your life whether you know it or not.” (Bedayn, 2024) We can’t treat it like a black box and hope for the best.
Task runners are morphing into reasoning assistants. But “LLMs are not good at capturing key characteristics of user data on their own.” (Shin et al., 2024) They accelerate work; they don’t replace judgment.
The risk is quiet failure. Automation bias shows up as people agreeing with bad model output: “Automation bias was measured as the agreement rate with wrong AI-enabled recommendations.” (Kücking et al., 2024) Non-specialists are the most at risk and are “... also the most susceptible to automation bias.” (Kücking et al., 2024)
Designing checkpoints that actually catch errors
Plan / delegate / review beats one-shot prompting
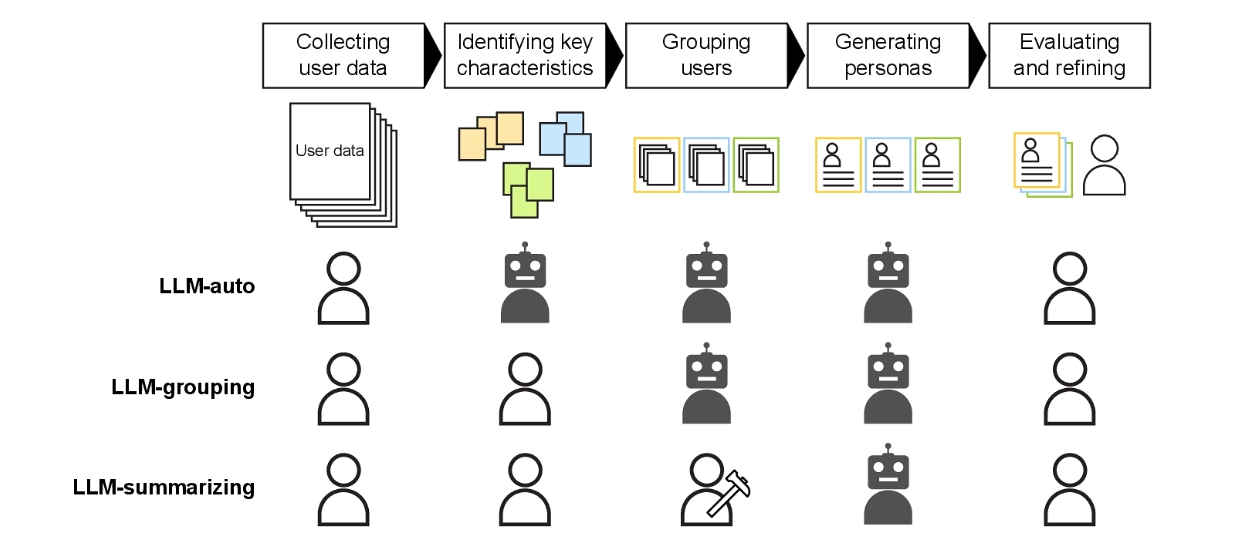
Stop shipping giant prompts and start storyboarding the work. Break the problem into a sequence of micro-decisions: scope the question, define inputs, generate a draft, test against acceptance checks, then revise or escalate. LLMs move fast, but “are not good at capturing key characteristics of user data on their own,” so you reserve scoping and sense-making for humans and let the model handle brute-force drafting and clustering (Shin et al., 2024). That division is the point: “Understanding which subtasks should be delegated to human experts versus AI is critical,” and teams that do this well outperform both automation-only and humans-only flows (Shin et al., 2024). In practice, you’re engineering the hand-offs, not just the prompt.
Think in blocks, not blobs
- Start with the scope. Define the decision, constraints, and what “good” looks like. If the task involves grouping or segmentation, keep that with the human to human skill in grouping user data by their key characteristics, improving outcomes (Shin et al., 2024). You’re shaping the ground truth before any tokens are generated.
- When generating, have AI draft, classify, extract, or cluster. Keep this reversible and narrow. One prompt per sub-task is usually better than one mega-prompt for all.
- Run acceptance checks by type: facts (named entities, numbers), policy (brand, legal), and structure (does it answer the question?). If a check fails, revise or escalate; don’t paper over it.
- A person makes the call on anything with external exposure, money, people, or safety on the line. Reserve “auto-ship” for low-impact, reversible steps.
Design acceptance checks that actually bite
Write the checks as short, binary questions tied to the step. Example: “Are all claims traced to a cited source?” “Do numbers reconcile to the source data?” “Does the output match the requested voice?” Keep them visible to both the prompter and the reviewer. This makes review faster and more consistent than open-ended “looks good?” approvals.
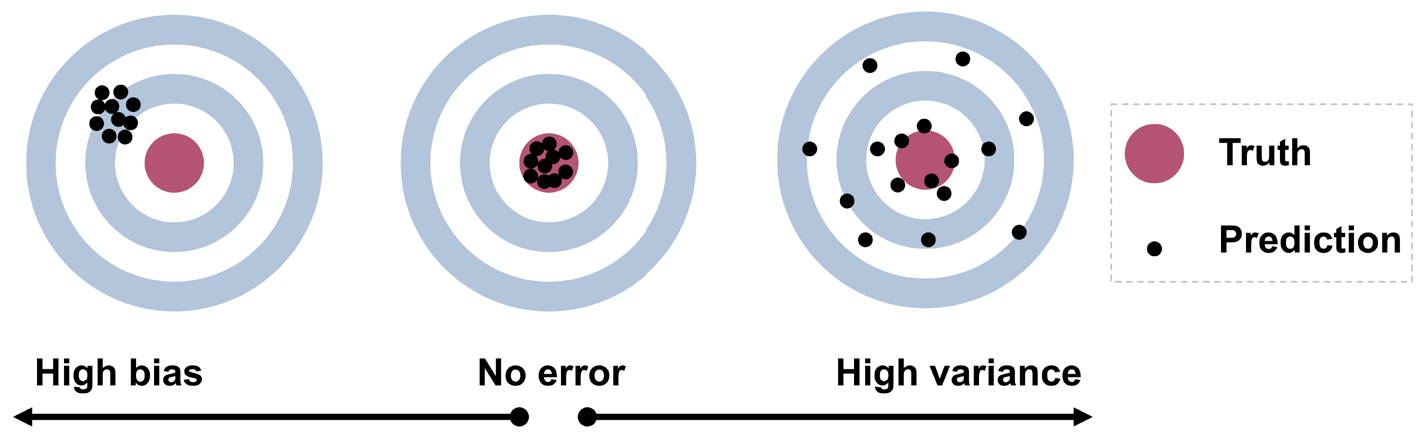
Add tripwires for uncertainty and bias
Instrument the places where quiet failure shows up. Use conflict detection (two divergent answers), low-confidence or missing-rationale flags, and the classic automation-bias signal of agreement with wrong AI-enabled recommendations as hard stops (Kücking et al., 2024). Non-specialists are especially vulnerable, so their flows should escalate more readily or include an independent check (Kücking et al., 2024). The aim isn’t to slow work; it’s to catch the specific failures that slip past intuition.
Minimal artifacts, maximal leverage
You don’t need heavy process to get leverage. Keep a lightweight step record (inputs, prompt/config, acceptance results, decision) so problems are explainable and reversible. If a check fails repeatedly, split the step again or move it to a human. This is how you turn debugging time into durable speed.
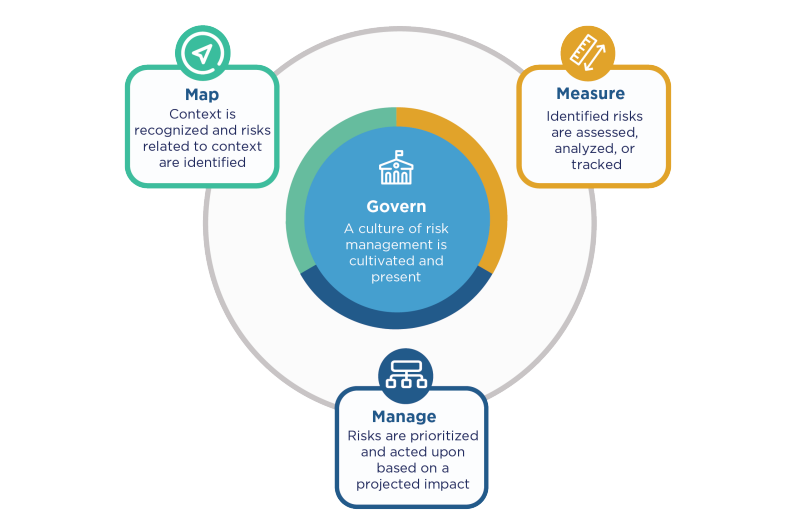
Smooth handoff to governance
Once your steps and checks are clear, assign the smallest set of roles that can keep pace: who owns the decision, who reviews high-impact steps, and when an approver is required. Oversight should stay “commensurate with the risks, level of autonomy and context of use,” which is your cue to keep RACI thin for low-impact flows and add independence only where it buys down risk (European Union, 2024)
Lightweight RACI for AI decisions
Name clear roles and keep handoffs visible. The operator’s job is to avoid blind acceptance. That is, to remain aware of the possible tendency of automatically relying or over-relying on the output, and then act on that awareness with simple checks and escalation paths. In practice, that means you decide up front who owns the decision, who reviews it, and who approves it when impact is high.
Owner: Sets scope, risk tier, and acceptance criteria. Chooses automation level for each task and defines the “stop” rules. If signals point to uncertainty or harm, the Owner pauses the run and routes it for review. Ownership is about judgment, not button-pushing.
Reviewer: Verifies inputs, data boundaries, and the model’s chain of reasoning. Looks specifically for automation bias, measured in studies as “agreement with wrong AI-enabled recommendations”, and sends work back when rationale is thin or confidence is inflated. Separation of duties matters here; the Owner shouldn’t self-review.
Approver: Accepts residual risk on decisions that touch people, money, reputation, or safety. As NIST notes, “Organizations can restrict AI applications that cause harm, exceed stated risk tolerances, or that conflict with their tolerances or values,” which implies the Approver must be empowered to halt or roll back when tolerances are crossed. Approval is a risk call, not a rubber stamp.
When roles can be combined
For low-impact, reversible work, the Owner may act as Reviewer; no Approver needed. For medium and high impact, keep roles separate and require an independent Reviewer. Add a second reader when the outcome is novel or ambiguous.
Handoffs and SLAs.
Define the Owner > Reviewer handoff as a short checklist: scope, inputs, prompt/config, acceptance criteria, and any flagged edge cases. Set service levels that match risk: hours for high impact, next business day for medium, and batch review for low. Oversight depth should be “commensurate with the risks, level of autonomy and context of use,” but the goal is steady throughput with fewer surprises.
Escalation triggers
Escalate when the model’s answers conflict, when confidence is low, or when you detect signs of over-reliance. Use the automation-bias signal, agreement with clearly wrong output, as a tripwire. If any trigger fires, the Owner moves the decision up to the Reviewer or Approver and records the rationale before proceeding.
The operating system for human + AI work
You don’t win balance with bigger prompts; you win it with smaller, named steps and clear ownership. Keep the centaur split: humans scope and synthesize, AI drafts and classifies, and a person decides when stakes rise. That rhythm of scope, generate, check, and decide is what turns speed into reliability.
Treat oversight as elastic. Low-impact, reversible work can ship on sample review. Medium impact gets an independent reviewer. High impact adds an approver empowered to halt or roll back when risk or ambiguity spikes. This isn’t bureaucracy; it’s guardrails that keep throughput high while catching quiet failures.
Make roles explicit. The Owner sets scope, risk tier, and stop rules. The Reviewer runs acceptance checks and hunts for over-reliance. The Approver accepts residual risk only when outcomes touch people, money, reputation, or safety. Clear handoffs and lightweight SLAs prevent stall-outs while raising the quality bar.
Remember the posture: AI assists; people decide. As one public-sector guide puts it, “It is important to see AI as a tool that helps humans, not one that takes their place,” and that framing keeps teams from chasing full automation where it doesn’t pay off. Use it to explain to leadership why reversible tasks can be automated end-to-end, while novel or externally exposed work stays human-in-the-loop (Public Sector Network, 2024). The point isn’t constraint; it’s confidence.
There’s also a cultural reality: “AI does in fact affect every part of your life whether you know it or not,” which means opting out of governance isn’t an option; it just shifts the risk to customers and staff (Bedayn, 2024). Build tripwires for uncertainty and bias into your flow, and you’ll catch the failures that intuition misses before they reach production.
Finally, accept that this won’t stand still. “There is no finish line for responsible AI,” and that’s good news; it gives you permission to iterate - tighten checks that bite, retire ones that don’t, and keep roles as thin as impact allows (Microsoft, 2024). Do that, and balance stops being a slogan and becomes the way your team ships work.
References
- Bedayn, J. (2024, March 4). AI pervades everyday life with almost no oversight; states scramble to catch up. Associated Press. https://apnews.com/article/d3226c9139d3d06af263e7ff467d0666
- European Union. (2024). Artificial Intelligence Act (Regulation (EU) 2024/1689). Official Journal of the European Union. https://eur-lex.europa.eu/eli/reg/2024/1689/oj
- Kücking, F., Hübner, U., Przysucha, M., Hannemann, N., Kutza, J.-O., Moelleken, M., Erfurt-Berge, C., Dissemond, J., Babitsch, B., & Busch, D. (2024). Automation bias in AI-decision support: Results from an empirical study. Studies in Health Technology and Informatics, 317, 298–304. https://doi.org/10.3233/SHTI240871
- Microsoft. (2024). Responsible AI Transparency Report 2024. Microsoft. https://www.microsoft.com/en-us/corporate-responsibility/responsible-ai-transparency-report/
- National Institute of Standards and Technology. (2024). NIST AI 600-1: Generative AI Profile. https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
- Public Sector Network. (2024, October 20). Leveraging the strength of centaur teams: Combining human intelligence with AI’s abilities. https://publicsectornetwork.com/insight/leveraging-the-strength-of-centaur-teams-combining-human-intelligence-with-ais-abilities
- Shin, J., Hedderich, M. A., Rey, B. J., Lucero, A., & Oulasvirta, A. (2024). Understanding human–AI workflows for generating personas. In Proceedings of the ACM on Designing Interactive Systems Conference (DIS 2024) (pp. 757–781). ACM. https://doi.org/10.1145/3643834.3660729



