It's not just the em-dashes that are flagging your content as AI generated. It's the invisible Unicode.
Models like ChatGPT, Claude, Gemini and others constantly put in invisible Unicode characters into their generations. It's a digital fingerprint that shows that the content is AI generated. If you were to copy and paste the output into Google Docs or something else, the Unicode gets copied over.
It's not intentional watermarking, but it's kind of more or less because of the training data. Simply put, there's different Unicode encodings for different data sources, and it gets mushed together with the training data.
You can have systems like UTF-8, which is usually used for English and common punctuation. There's UTF-16, which is used for languages that have more characters outside of the basic ASCII range. There's UTF-32, which is the simplest way to show Unicode code points. There's other systems too.
There's also the fact that AI models process text as tokens. So certain Unicode characters are embedded in learned patterns, or because they keep formatting structures that were encountered during training.
This isn't new. If you're familiar with tools like TurnItIn, plagiarism checkers check the Unicode as one of their methods to see if you cheated or not. If you're copying and pasting a ton of Unicode from a different source, and it's different from the stuff you were writing, it's pretty apparent that you were cheating.
Similarly, you will see publishers and platforms use Unicode analysis to check if the content is authentic or not.
So while we're seeing more and more tools try to false-flag content as AI generated based on solely using em-dashes or other things (I had a person with a research background complain how that's what he was taught to use), checking for Unicode is a better way to go about things. Otherwise it will do more harm than good.
To show the different invisible characters, I made a react app within ChatGPT. You can use my prompt to create your own, just turn on canvas and hit send.
Prompt to show Unicode Characters
{
"system": "You are a senior frontend engineer specializing in educational tools. Your task is to generate complete, runnable React code using Tailwind CSS and shadcn/ui components for the ChatGPT Canvas environment. The code should include UI, logic, and inline comments where helpful. All code must be production-ready, minimal, and clean.",
"user": "Create a Unicode Education Tool in React. The tool should let users input a text string and select from a dropdown of hidden Unicode characters (at least 10 options, e.g., U+200B, U+00A0, U+200C, U+200D, U+FEFF, U+202F, etc.). After submission, it should output:\n\n1. The original string with the selected Unicode inserted randomly within the characters.\n2. A "revealed" version showing the inserted Unicode characters inline as their codepoint names (e.g., [U+200B]).\n3. Below both outputs, it should list and explain the selected Unicode’s function.\n4. Also show a reference table explaining what each of the 10 hidden Unicode characters does, to educate users.\n\nUse dropdowns, textarea input, two output cards, and a fixed Unicode reference section at the bottom. Keep everything within a single canvas page. Include comments. Do not include markdown, metadata, or preamble — output only code.",
"assistant_rules": "Always output only runnable React + Tailwind code for Canvas. Include necessary components, layout, logic, and styling. Do not output explanations, markdown, or surrounding text. Use clear labels and structured UI. Make sure you do a web-search to research {{topic}} and double-check every claim.",
"variables": {
"web_access": "true",
"citation_style": "none",
"max_clarifying_qs": 2,
"wrap_in_code_fence": "false",
"max_tokens": 500
},
"expected_output_format": "Full React code implementing the specified UI and logic within ChatGPT Canvas. All UI elements should be functional. Styling should use Tailwind. Components should be imported from shadcn/ui and lucide-react if needed.",
"examples": []
}
Quick Unicode Cheat Sheet
Zero-Width Space - U+200B
Non-Breaking space - U+00A0
Zero-Width Non-Joiner - U+200C
Zero-Width Joiner - U+200D
Byte Order Marks - U+FEFF
Narrow No-Break space - U+202F
Word Joiner - U+2060
LTR Mark - U+200E
RTL Mark - U+200F
LTR Isolate - U+2066
RTL Isolate - U+2067
First Strong Isolate - U+2068
Pop Directional Isolate - U+2069
Combining Grapheme Joiner - U+034F
Common Invisible Characters
Zero-Width space
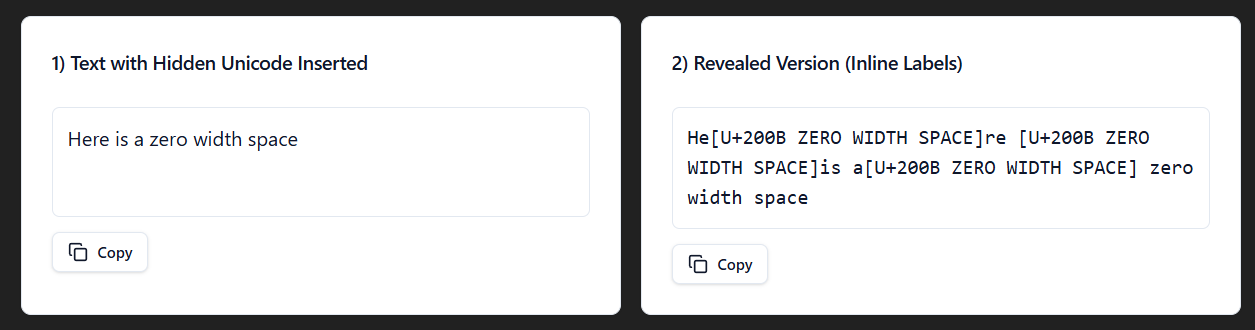
A Zero-Width Space Unicode (U+200B) is often used for a soft wrap. You can see how it's hidden within 'He' and 're', before 'is', and right after 'a'. It's used to prevent a line break in long words, or a URL to improve readability.
Non-Breaking space
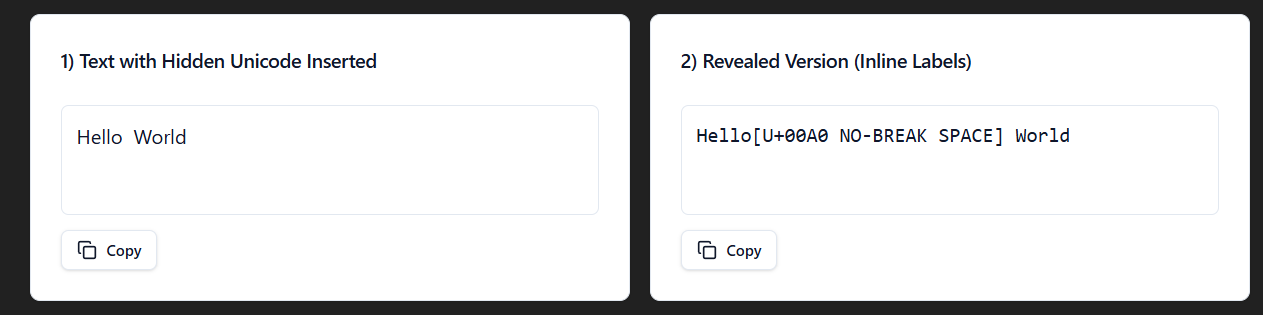
The Non-Breaking space Unicode (U+00A0) looks like a normal space, but prevents line breaks in text. So like if you have a line like Dr. Mark, it keeps it together in one line.
Zero-Width Non-Joiner
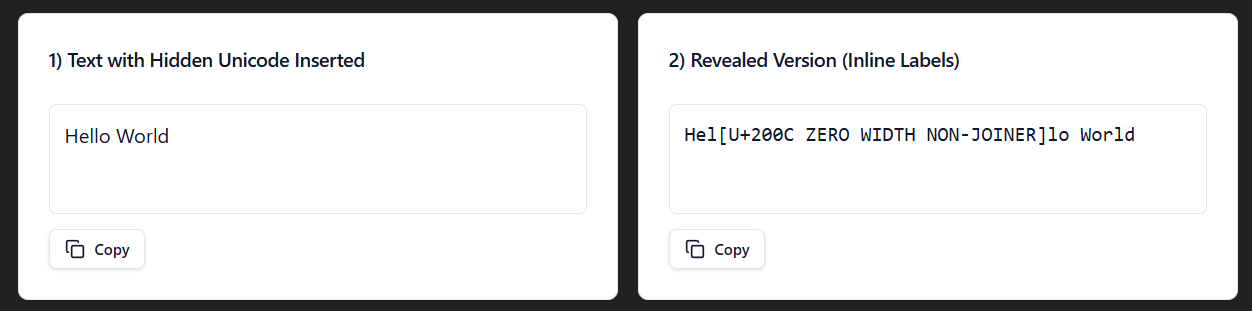
The Zero-Width Non-Joiner Unicode (U+200C) helps prevent characters from joining. Usually used with cursive scripts like Arabic where two characters are combined into a single glyph, but can be seen in English (for example keeping an A from becoming merged together with the following E into Æ).
Zero-Width Joiner
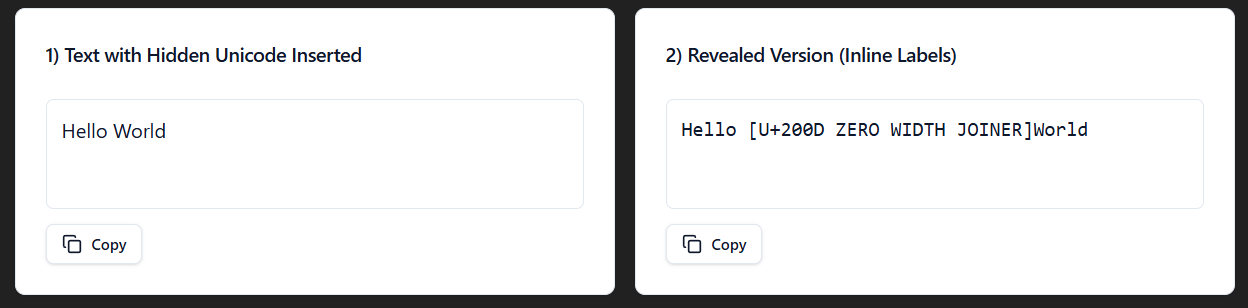
The Zero-Width Joiner Unicode (U+200D) forces characters to join. If you have an emoji, there's a good chance this one was used to combine individual emoji characters into more complex shapes. Like the family emoji, or a flag. Basically prevents breaks in characters that would otherwise be separated.
Byte Order Marks (BOM)
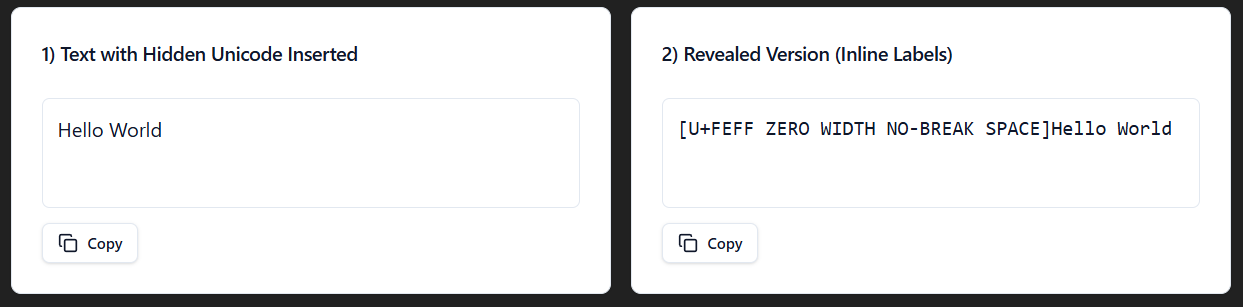
Historically a BOM Unicode (U+FEFF), it is a technical character that acts like a Zero-Width Non-Break space in text. It's sometimes also seen as a signature in UTF-8 files on Windows.

Narrow No-Break Space
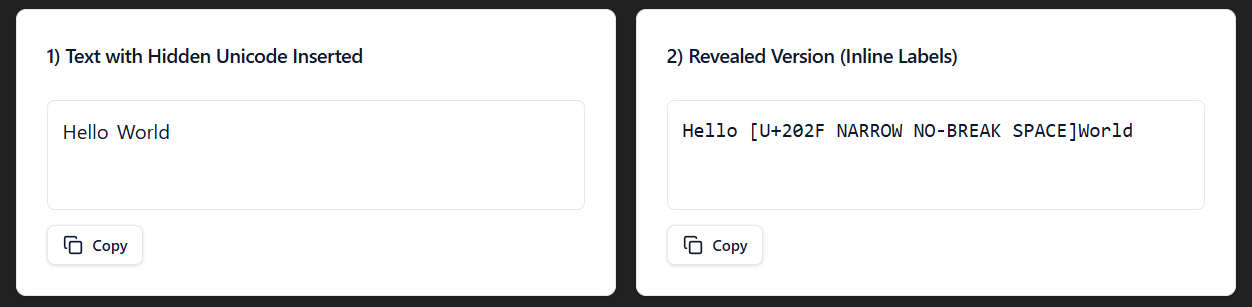
The Narrow No-Break Space Unicode (U+202F) is a thinner non-breaking space that started popping with the GPT-03 and GPT-04 models. It's mostly used to prevent line breaks around certain punctuation marks or within numbers, keeping them in a certain line.
Word Joiner
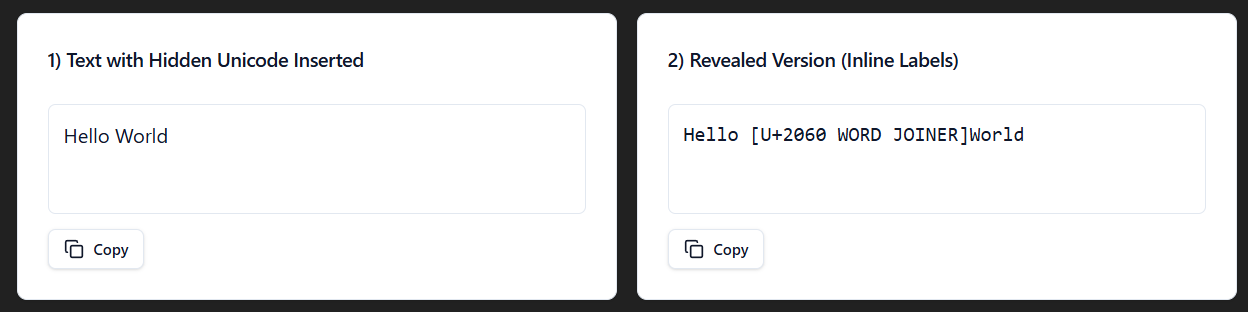
The Word Joiner Unicode (U+2060) is used to prevent line breaks without being treated as a white space. It keeps characters from line breaking where they would normally occur, which is relevant for languages that don't use spaces between words.
LTR Mark
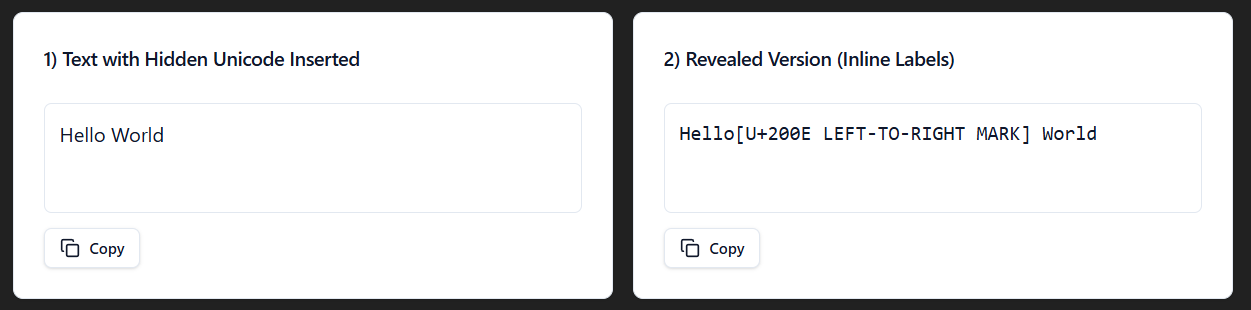
The LTR Mark Unicode (U+200E) marks text as left to right for bi-directional rendering. This is helpful to prevent left to right languages, like English, from being incorrectly displayed in other languages.
RTL Mark
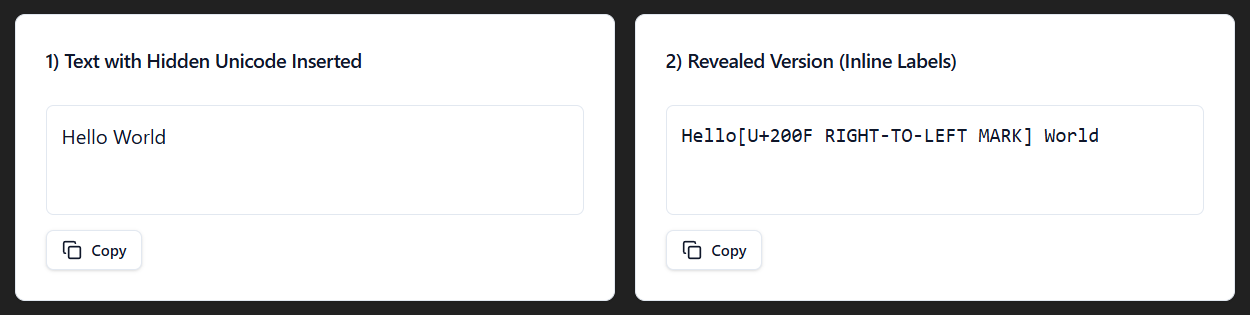
The RTL Mark Unicode (U+200F) is to mark the text as, believe it or not, right to left for bi-directional rendering of the text. For example, if you have a comma when using a right to left language, it makes sure it's added to the right spot with this.
LTR Isolate
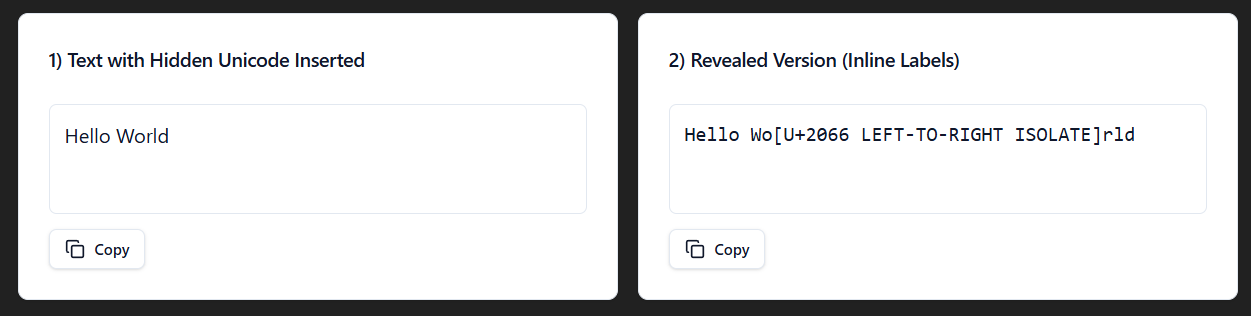
The LTR Isolate Unicode (U+2066) starts an isolated span for a safe directional embedding in the text from left to right. So if you have an English phrase within your RTL text, it makes sure that the English phrase is correctly displayed without breaking things.
RTL Isolate
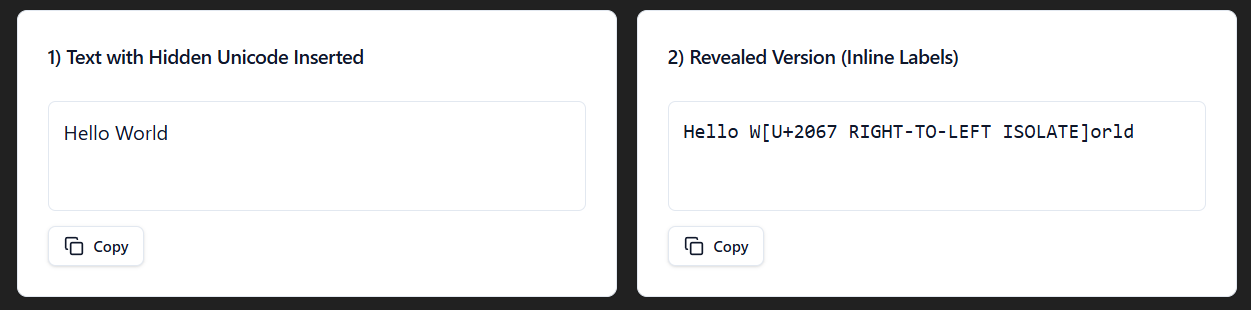
The RTL Isolate Unicode (U+2067) starts also an isolated span for a safe directional embedding in the text, but right to left instead. An example would be an English sentence that includes an Arabic or Hebrew phrase. The RTL Isolate Unicode would make sure that the right to left text is correctly displayed and doesn't affect the surrounding text.
First Strong Isolate
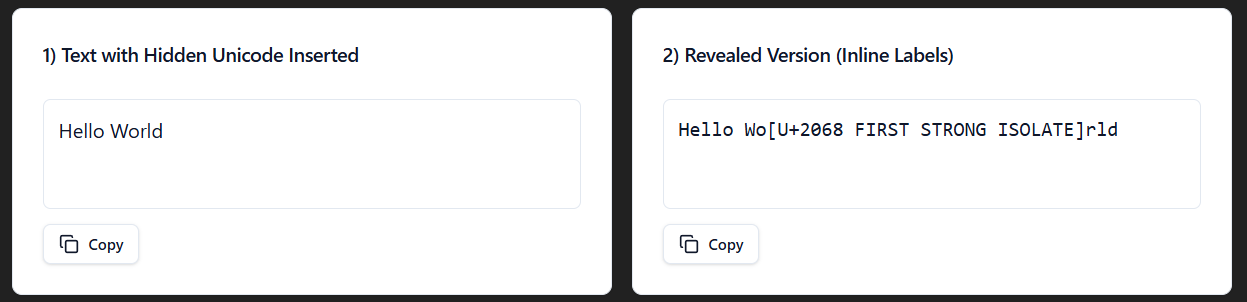
The First Strong Isolate Unicode (U+2068) is an isolated span, where the direction is set by the first strong character. So like if you have two languages in a single document, like Arabic and English, the Unicode is needed to make sure that there is a correct display.
Pop Directional Isolate
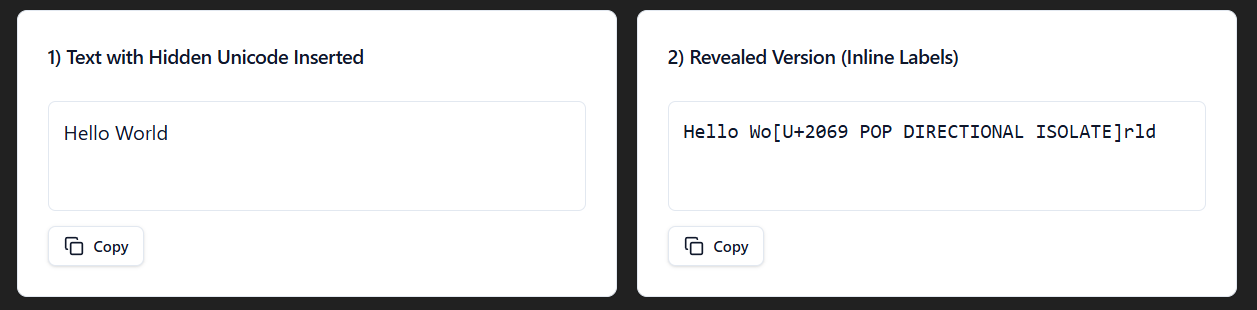
The Pop Directional Isolate Unicode (U+2069) ends an isolate span started by a Left-Right Isolate, or a Right-Left Isolate, or a First Strong Isolate Unicode.
Combining Grapheme Joiner
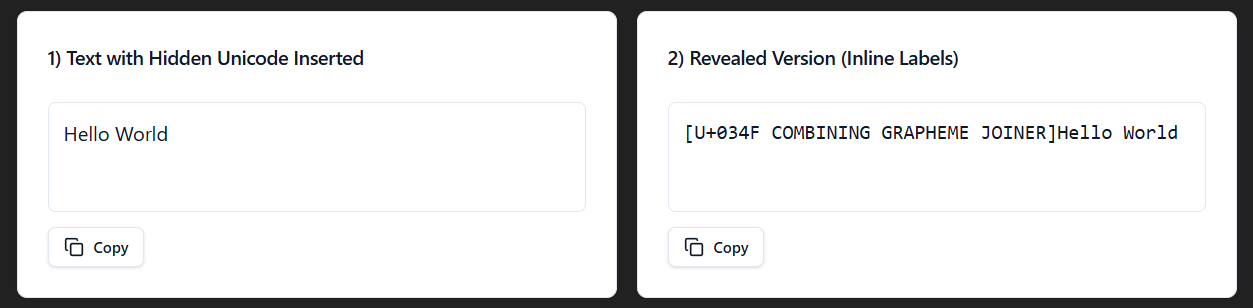
The Combining Grapheme Joiner Unicode (U+034F) affects grapheme segmentation, which is traditionally the smallest units of a writing system that correspond to a single sound. Think "sh" in a word. It's also invisible.
That's a lot right?
Again, to stress. These aren't intentional watermarks, but are a result of the training data, like HTML documents, PDFs, rich-text formats that usually have these Unicode's inserted. That said, some of the Unicode's listed above are necessary, like if you are combining different languages together with your text.
That said, if for instance the Unicode for right to left languages is included in an English or French only text, that would be proof that the text isn't written by a human.
So what can you do?
There's a few ways to detect and remove invisible Unicode characters. Manually, I would use Notepad++, since it shows non-printable characters with special symbols. You can do the same with Visual Studio Code.
Steps to Reliably remove Invisible Unicode in Notepad++
- Paste your text in Notepad++
- Use a regular expression in Find & Replace (Ctrl+H) to search for ranges. For example [\u200B\u200C\u200D\uFEFF] and replace them with nothing
But as we're seeing more and more tools try to false-flag content as AI generated (which was written by hand), these are things that people normally don't do when they write.

